This is a project demonstrates how AI runs on embedded system RTL8722DM
While TensorFlow Lite (TFL) for Microcontrollers is designed to run machine learning models on microcontrollers and other devices with only a few kilobytes of memory. In this project, we will demonstrate how Ameba RTL8722DM supports TensorFlow Lite build-in example "Magic Wand".
Introduction to Google TensorFlow
TensorFlow (TF) is an end-to-end open-source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries, and community resources that lets researchers push the state-of-the-art in ML, and developers easily build and deploy ML-powered applications.
TensorFlow Lite for Microcontrollers
While TensorFlow Lite (TFL) for Microcontrollers is designed to run machine learning models on microcontrollers and other devices with only a few kilobytes of memory. The core runtime just fits in 16 KB on an Arm Cortex M3 and can run many basic models. It doesn't require operating system support, any standard C or C++ libraries, or dynamic memory allocation.
Ameba and TFL for Microcontrollers
Ameba is an easy-to-program platform for developing all kinds of IoT applications. AmebaD is equipped with various peripheral interfaces, including WiFi, GPIO INT, I2C, UART, SPI, PWM, ADC. Through these interfaces, AmebaD can connect with electronic components such as LED, switches, manometer, hygrometer, PM2.5 dust sensors, …etc.
Magic Wand Example Running on Ameba RTL8722DM
Materials
• Ameba D [RTL8722 CSM/DM] x 1
• Adafruit LSM9DS1 accelerometer
• LED x 2
Example Procedure
Connect the accelerometer and LEDs to the RTL8722 board following the diagram.
/* Copyright 2019 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include <TensorFlowLite.h>
#include "main_functions.h"
#include "accelerometer_handler.h"
#include "constants.h"
#include "gesture_predictor.h"
#include "magic_wand_model_data.h"
#include "output_handler.h"
#include "tensorflow/lite/micro/kernels/micro_ops.h"
#include "tensorflow/lite/micro/micro_error_reporter.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "tensorflow/lite/version.h"
// Globals, used for compatibility with Arduino-style sketches.
namespace
{
tflite::ErrorReporter *error_reporter = nullptr;
const tflite::Model *model = nullptr;
tflite::MicroInterpreter *interpreter = nullptr;
TfLiteTensor *model_input = nullptr;
int input_length;
// Create an area of memory to use for input, output, and intermediate arrays.
// The size of this will depend on the model you're using, and may need to be
// determined by experimentation.
constexpr int kTensorArenaSize = 60 * 1024;
uint8_t tensor_arena[kTensorArenaSize];
// Whether we should clear the buffer next time we fetch data
bool should_clear_buffer = false;
} // namespace
// The name of this function is important for Arduino compatibility.
void setup()
{
// Set up logging. Google style is to avoid globals or statics because of
// lifetime uncertainty, but since this has a trivial destructor it's okay.
static tflite::MicroErrorReporter micro_error_reporter; // NOLINT
error_reporter = µ_error_reporter;
// Map the model into a usable data structure. This doesn't involve any
// copying or parsing, it's a very lightweight operation.
model = tflite::GetModel(g_magic_wand_model_data);
if (model->version() != TFLITE_SCHEMA_VERSION)
{
TF_LITE_REPORT_ERROR(error_reporter,
"Model provided is schema version %d not equal "
"to supported version %d.",
model->version(), TFLITE_SCHEMA_VERSION);
return;
}
// Pull in only the operation implementations we need.
// This relies on a complete list of all the ops needed by this graph.
// An easier approach is to just use the AllOpsResolver, but this will
// incur some penalty in code space for op implementations that are not
// needed by this graph.
static tflite::MicroMutableOpResolver<5> micro_op_resolver; // NOLINT
micro_op_resolver.AddBuiltin(
tflite::BuiltinOperator_DEPTHWISE_CONV_2D,
tflite::ops::micro::Register_DEPTHWISE_CONV_2D());
micro_op_resolver.AddBuiltin(tflite::BuiltinOperator_MAX_POOL_2D,
tflite::ops::micro::Register_MAX_POOL_2D());
micro_op_resolver.AddBuiltin(tflite::BuiltinOperator_CONV_2D,
tflite::ops::micro::Register_CONV_2D());
micro_op_resolver.AddBuiltin(tflite::BuiltinOperator_FULLY_CONNECTED,
tflite::ops::micro::Register_FULLY_CONNECTED());
micro_op_resolver.AddBuiltin(tflite::BuiltinOperator_SOFTMAX,
tflite::ops::micro::Register_SOFTMAX());
// Build an interpreter to run the model with.
static tflite::MicroInterpreter static_interpreter(
model, micro_op_resolver, tensor_arena, kTensorArenaSize, error_reporter);
interpreter = &static_interpreter;
// Allocate memory from the tensor_arena for the model's tensors.
interpreter->AllocateTensors();
// Obtain pointer to the model's input tensor.
model_input = interpreter->input(0);
if ((model_input->dims->size != 4) || (model_input->dims->data[0] != 1) ||
(model_input->dims->data[1] != 128) ||
(model_input->dims->data[2] != kChannelNumber) ||
(model_input->type != kTfLiteFloat32))
{
TF_LITE_REPORT_ERROR(error_reporter,
"Bad input tensor parameters in model");
return;
}
input_length = model_input->bytes / sizeof(float);
TfLiteStatus setup_status = SetupAccelerometer(error_reporter);
if (setup_status != kTfLiteOk)
{
TF_LITE_REPORT_ERROR(error_reporter, "Set up failed\n");
}
}
void loop()
{
// Attempt to read new data from the accelerometer.
bool got_data =
ReadAccelerometer(error_reporter, model_input->data.f, input_length, should_clear_buffer);
if (should_clear_buffer)
{
error_reporter->Report("\r\nPredicted gestures:\n\r");
}
// Don't try to clear the buffer again
should_clear_buffer = false;
// If there was no new data, wait until next time
if (!got_data)
return;
// Run inference, and report any error.
TfLiteStatus invoke_status = interpreter->Invoke();
if (invoke_status != kTfLiteOk)
{
TF_LITE_REPORT_ERROR(error_reporter, "Invoke failed on index: %d\n",
begin_index);
return;
}
// Analyze the results to obtain a prediction
int gesture_index = PredictGesture(interpreter->output(0)->data.f);
// Clear the buffer next time we read data
should_clear_buffer = gesture_index < 3;
// Produce an output
HandleOutput(error_reporter, gesture_index);
}
Upload the code and press the reset button on Ameba once the upload is finished.
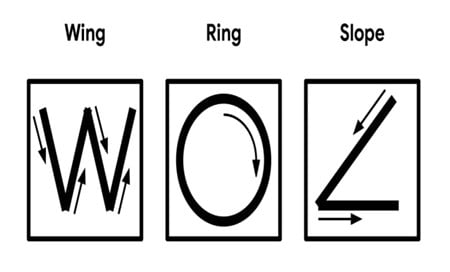
Holding the accelerometer steady, with the positive x-axis pointing to the right and the positive z-axis pointing upwards, move it following the shapes as shown, moving it in a smooth motion over 1 to 2 seconds, avoiding any sharp movements.
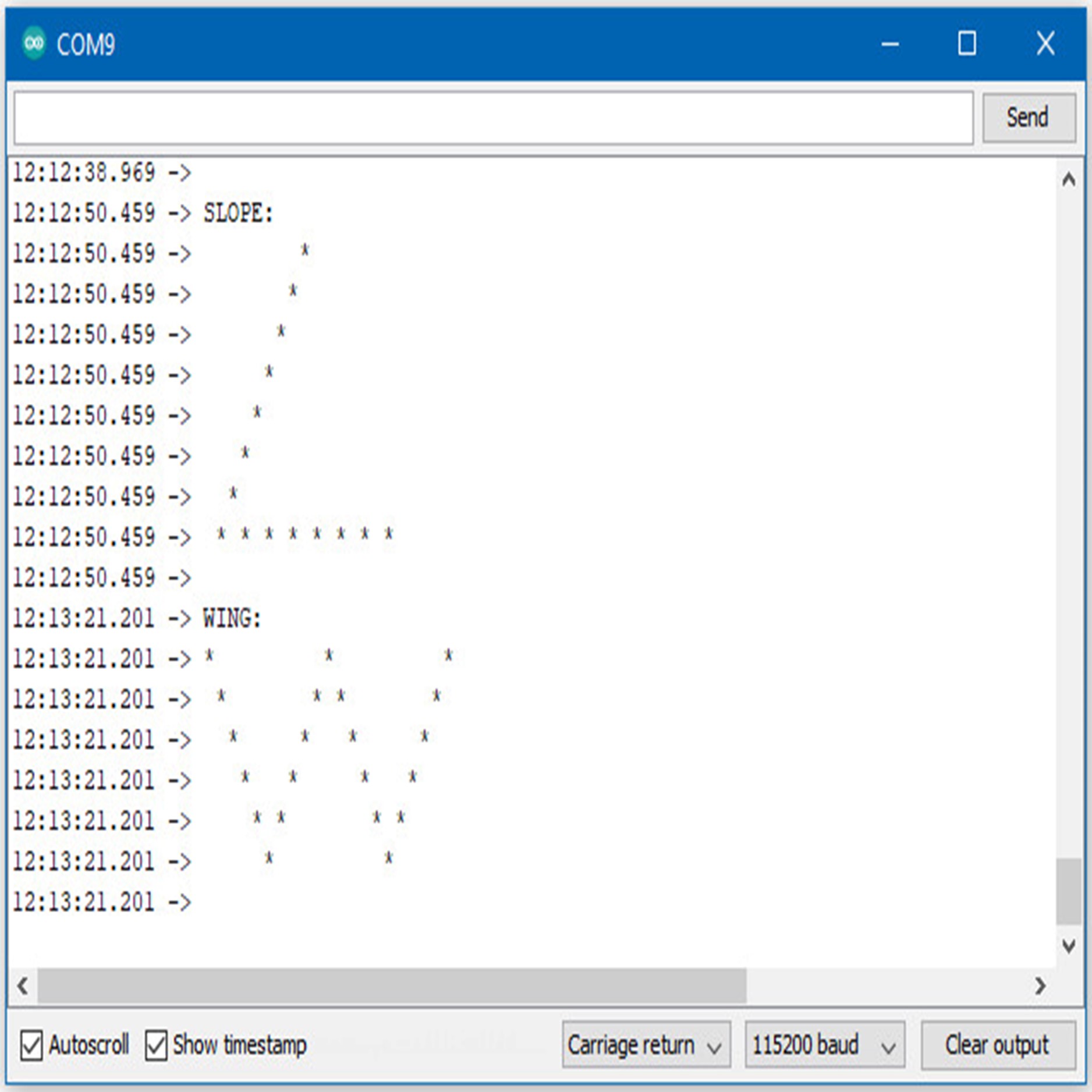
If the movement is recognized by the Tensorflow Lite model, you should see the same shape output to the Arduino serial monitor. Different LEDs will light up corresponding to different recognized gestures.
Note that the wing shape is easy to achieve, while the slope and ring shapes tend to be harder to get right.
Reference and Q&A