Create a real-time multiple object detection and recognition application in Python using with a Raspberry Pi Camera
Jetson Nano is a GPU-enabled edge computing platform for AI and deep learning applications. The GPU-powered platform is capable of training models and deploying online learning models but is most suited for deploying pre-trained AI models for real-time high-performance inference. Using additional Nvidia tools, deployed standard AI models can have enhanced fidelity performance.
This article is a project showing how you can create a real-time multiple object detection and recognition application in Python on the Jetson Nano developer kit using the Raspberry Pi Camera v2 and deep learning models and libraries that Nvidia provides.
How Difficult are Object Detection and Recognition?
Object detection is the technique of determining the presence of an object and estimating its location in the image canvas. Object recognition classifies the detected object from the list of previously seen (trained on) objects. Detection techniques usually form a rectangular bounding box around the object and is a coarse representation of the extent of the object in the image. Recognition techniques usually classify the object with a certain probability or belief in the prediction.
In an image with multiple objects, it is a challenging task to determine the location of all the individual objects (detection) and then recognize them, due to several reasons:
- There can be a possible overlap between multiple objects causing occlusions for one or all.
- Objects in the image can have varying orientations.
- The objects could only be partially present in the image.
- Images from low fps video stream can be blurry and distort the features of the object.
Image detection and recognition
TensorRT on Jetson Nano
The Nvidia JetPack has in-built support for TensorRT (a deep learning inference runtime used to boost CNNs with high speed and low memory performance), cuDNN (CUDA-powered deep learning library), OpenCV, and other developer tools.
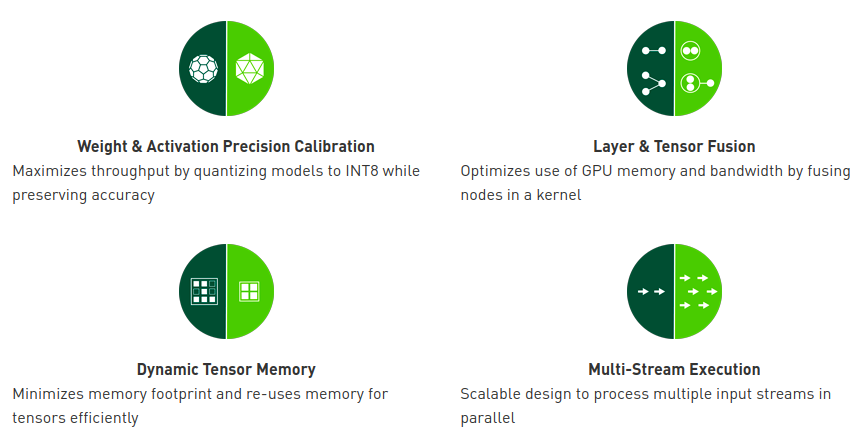
TensorRT SDK is provided by Nvidia for high-performance deep learning inference. It has an inference optimizer that runs deep learning models with low latency even in real-time situations. Nvidia claims inference on deep learning applications is up to 40 times faster than CPU-only platforms. It is built on CUDA and the parallel programming feature enables optimization for multiple frameworks and development tools. The Jetson Nano board provides FP16 compute power and using TensorRT’s graph optimizations and kernel fusion, production-level performance can be obtained for NLP, image segmentation, object detection, and recognition applications.
Setting Up the Hardware
The hardware set up steps can be found in the previous article on Real-Time Face Detection on Jetson Nano Using OpenCV.
Setting Up the Software
The Jetson Nano developer kit needs some packages and tools to implement the object detection and recognition task. All installations will be made for Python3.
- Numpy - Scientific computing library supporting array objects.
- CMake - Meta- Build System for C++.
- Git - Version Contol System.
Run these in the Jetson Nano terminal to install these packages.
akshay@jetson-nano:~$ sudo apt-get install git cmake libpython3-dev python3-numpy
Installing Pre-trained Deep Learning Models
Nvidia provides an open-source repository with instructions for deploying deep learning models for vision applications and more.
// The repository has several other git sub-modules, so we use the --recursive keyword to correctly clone them as well
akshay@jetson-nano:~$ git clone --recursive https://www.github.com/dusty-nv/jetson-inference.git
akshay@jetson-nano:~$ cd jetson-inference
akshay@jetson-nano:~$ mkdir build && cd build
akshay@jetson-nano:~$ cmake ../
// Select the pre-trained models that you want to download on the Jetson Nano board. You can just select Ok and the default selections will be downloaded
// You can avoid installing PyTorch for now
akshay@jetson-nano:~$ make
// Build the C++ libraries and Python bindings as well as install the libraries and link them correctly
akshay@jetson-nano:~$ sudo make install
akshay@jetson-nano:~$ sudo ldconfig
Selection window for the models
Simple Python Application for Object Detection and Recognition
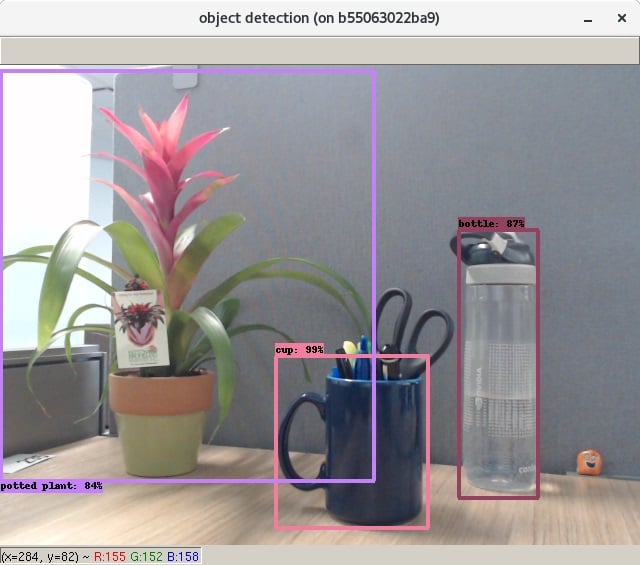
Among the provided models, we use the SSD-MobileNet-v2 model, which stands for single-shot detection on mobile devices. It is a part of the DetectNet family. This model is pre-trained on the MS COCO image dataset over 91 different classes. It can detect multiple objects in the same frame with occlusions, varied orientations, and other unique nuances. The model is pre-trained on common objects like soda cans, ovens, toasters, TVs, cakes, pizzas, and several other everyday items.
Use the example Python file my-detection.py to see live object detection and recognition in action.
// Navigate to the folde with all the Python codes
akshay@jetson-nano:~$ cd jetson-inference/build/aarch64/bin
// Run the Python code for to detect objects in the real time video stream
akshay@jetson-nano:~$ python my-detection.py
// This can initially take a few minutes to start when the model is loaded for the first time
The code in the file is fairly easy to understand. It imports all the necessary tools from the Jetson inference package and the Jetson utilities. Next, it creates an object for the exact pre-trained model (SSD-MobileNet-v2 here) to be used and sets a confidence threshold of 0.5 for object detection.
While previously we manually created a GStreamer pipeline to interact with the video stream from the Raspberry Pi camera, jetson.utils already provides a pre-configured pipeline. It also provides a display handle. Finally, the code captures every image in the video stream and runs the detection algorithm and then draws translucent bounding boxes around the objects.
Satisfactory recognition performance in Recognition
Results and Conclusions
Object detection and recognition are core AI techniques that find applications in self-driving cars, robotics, and traffic management. This technique is only meant for coarse detections and real-world scenarios often need more precision and higher resolution in their detections. The image segmentation technique suffices such requirements and is capable of pixel-level detection of objects and their further classifications.
The next step in this series will be to implement a runtime instance of a segmentation model and observe its performance and explore tweaking the same using TensorRT on the Jetson Nano GPU.