A solar-powered node that uses neural networks to detect illegal logging, poaching, and early-stage wildfires.
Content goes hereI’ve been tinkering with an idea that’s simple on paper but powerful in the field: a tiny, solar-powered forest guardian that sits on a tree and listens. The goal is to detect illegal logging (chainsaws), poaching noises, and eventually early signs of wildfire, then ping a gateway with an alert.
This write-up is about my MVP: a working prototype that runs a quantized ML audio model on the FRDM i.MX93 and reliably flags chainsaw activity. It’s not the final product (yet), but it proves the board can run a real model efficiently with practical latency and power in mind.
Why this build?
- Illegal logging & poaching are noisy. Chainsaws and vehicles give themselves away.
- Fire tends to have a sound signature (crackle/roar) that could be added later.
- A solar + battery node is realistic in remote forest deployments, no one wants to hike in just to swap AA batteries every week (unless the pay is good)
TL;DR results (for the MVP)
- Main task: Detect chainsaw vs. background forest audio (3-second windows).
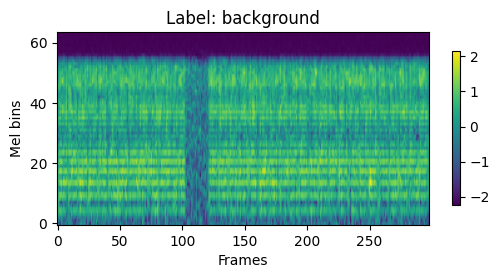
- Model: A compact CNN on log-mel spectrograms from 3 second wav recordings of forests, exported as TFLite INT8 so it can run on the board.
- On-device behavior: Real-time audio → log-mel → model → debouncing → alert.
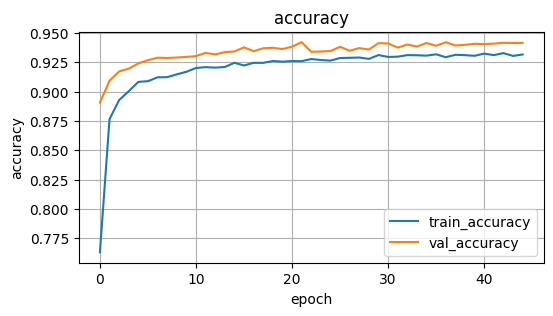
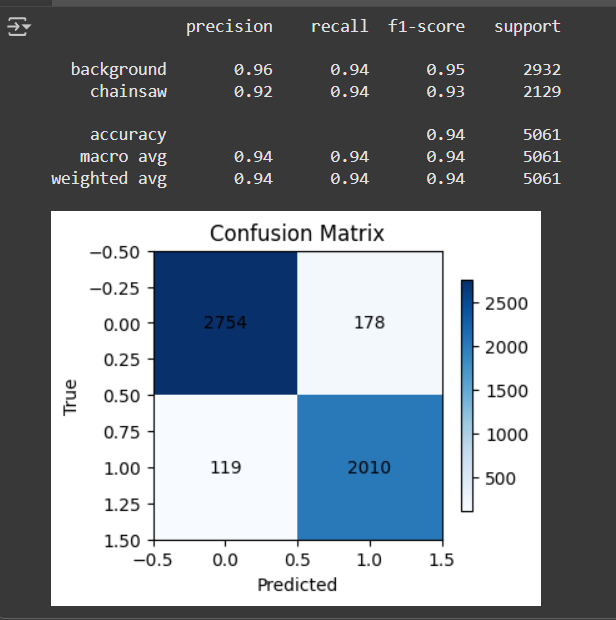
- What I saw in testing: around ~94% overall accuracy with good recall for chainsaw events (based on my validation/test runs). That’s strong enough to push forward to the full device version.
(Numbers will improve as I add more “hard negatives” and tune the operating threshold for field conditions.)
Hardware & OS choices
Of course, I used the FRDM I.MX93 dev board kindly provided by NXP. Their guides were excellent, so I had it running in no time. For the OS, I used the prebuilt Linux image that NXP has published, which let me quickly validate my pipeline without having to tinker with lower-level systems. For the final product, the ideal approach would be to build a tailored Yocto image from scratch; that way, the board runs only minimal services, resulting in faster boot times and lower power usage. I started on this but didn’t finish because of the deadline.
Audio & ML pipeline
1. Audio capture: For now, I’m capturing sound with a USB mic; this was the fastest way to prototype. For the final product, a better approach is to use the board’s other processor core to capture audio from an I²S mic connected to the GPIO.
2. Features: I sample the audio at 12 kHz and process 3-second windows so the input matches the data the model was trained on.
3. Model: Before this project I knew nothing about training a neural network, so I had some learning to do. Training was really slow on my computer (no GPU 😕), so spending hours only to end up with a model that detected background forest sounds as a chainsaw was frustrating. I switched to Google Colab, which lets you use GPUs for free, so I could train much faster and improve the model quality, I managed to finish training before the daily free limit ran out! For the technical details: I used a depthwise-separable CNN trained in TensorFlow/Keras on a Tesla T4 (Colab) with SpecAugment, early stopping, and class weighting, whatever that means; I’m still learning. Finally, I exported the model to TFLite INT8 and compiled it with Vela for the board’s NPU so it can run on-device.
4. Inference logic: The system continuously produces probability scores for chainsaw audio. I apply basic debouncing so it doesn’t trigger on a single window, and I include a configurable threshold so it can be calibrated on-site.
I trained the model on a nice dataset available here, with thousands of recordings of forest sounds and chainsaws rfcx/frugalai
Power & deployment
For the contest MVP I ran on the prebuilt Linux image and a USB mic to move fast, but the deployment vision is:
- Solar + Battery: small panel, rugged enclosure, and a battery sized for local weather (cloudy days included).
- Tailored Yocto: strip services, lean boot, use the low-power core for always-on audio; wake the high-level app only when needed.
- I²S mic: lower power than USB, better placement flexibility, clocking under our control.
- Edge alerts: send only events (not raw audio) over LoRaWAN/LTE—privacy-preserving and cheap on bandwidth.
- Multi-class model: add vehicles, gunshots, voices, and fire signatures. Same pipeline, more labels.
How I’d improve next
- More data & hard negatives: background that _sounds_ chainsaw-ish is the best teacher.
- Threshold per-site: learn the best operating point per forest (some places are noisier).
- Self-test mode: periodic chirp to check the mic path is alive; log health to flash.
- On-device feature extraction: move log-mel to the audio core to save power on the main core.
- Web UI: for better visualization, here's a little demo I made.
If you are into the technical stuff here are some of the results from my training
Model accuracy over training epoch
Finally, a video of the system working
Thank you for reading, and thanks to NXP, Maker Pro, All About Circuits, and everyone involved for letting me try out this board. It’s been a really interesting learning experience!